The
blog entry from Robert O'Callaghan that I linked to earlier via GR reminded me that I had a rant I wanted to explore a bit so bear with me. Before I start just let me be clear that I'm actually a major fan of the multi core cpu trend at the moment and I genuinely realize that multi-core systems and highly parallelized architectures (a la the PS3) are going to be a very important part of all things processing related in the future and we are going to need some major software rewrites to make efficient use of it. However a very interesting article that I came across at work brought back some of the stuff I learned at college all those decades ago and I thought a similar riff of my own here wouldn't be a bad idea. At least it might stop me trying to expound on this to folks in the pub.
Robert's article accurately points out that most current codebases perform very badly on multi processor systems and he deduces that since we are moving to a mega-multi-core world that a major die off of this bad old code will happen leading to an exciting new generation of software that only really shines when running on multi core systems. I think he's mostly right in the article but I think we need to think about what sort of multi core systems we are likely to see in the medium to long term before undertaking some of the really major rewrites. Also we need to start to focus on more than just the processors - the sequential nature of the communications protocols we use for almost everything is a major performance bottleneck but that's a rant for another day. Right now I just want to explore the potential performance envelope that this multi core trend will enable for us and when we can expect it to end.
As Robert pointed out most computing tasks that we have today don't fit the parallel paradigm too well, in fact some are so poorly suited to parallel architectures that they run slower on multi core cpu's than on older single core cpu's at the same clock speed. My hope, though, is that Robert's vision will come about sooner rather than later and we will get to a point where ~95% of of the workload that we want to do can be distributed [across multiple cores]. I'm not hugely confident that this will happen; certain things - signaling, thread\process coordination, general system housekeeping overhead, user interface feedback, authentication\authorization sequencing, challenge response handshaking\key exchange and some time sensitive code to name a few will forever remain almost entirely sequential. However, I'm not really an expert so I'll err on the side of extreme optimism here and use that 5%\95% ratio in my arguments.
Now we must hark back to 1967 when the great grand daddy of parallel computing architectures, Gene Amdahl,
sat back and thought long and hard about this. He realized that the little bitty fraction of code that had to forever remain sequential would ultimately prevent parallelism scaling indefinitely. Specifically he pointed out that there is a hard limit to the increased performance that can be realized by adding more computing cores that depends solely on the relative fraction of your code that has to remain sequential. In short where F is the fraction that can never be made parallel that limit is 1/F. More generally where N is the number of processors\cores available the maximum performance improvement attainable when using N processors is:

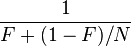
So in my assumed near nirvana state of 95% parallelizable we end up with a hard limit of 20 x performance gain even if we were to add a million cores. The drop off in marginal performance kicks in quickly and as N passes 100 or so with the additional benefit of each extra CPU drops to less than 15% of a single CPU on its own. Even assuming that we have highly efficient idle power management capabilities that is going to be a bugger to justify just from an electrical power perspective. My guess is that we'll stop building general purpose symmetric multi-cores long before that - probably stopping at no more than 32 although 16 might well be the sweet spot. Despite the fact that
Intel have demo'ed an 80 core CPU and have pledged to have them commercially available by 2010 I don't really think it will happen, or if it does then not all 80 cores will be equal. I wouldn't be an expert now mind you so this is just my opinion remember.
Amdahl's law above quite specifically deals with symmetric systems and doesn't deal with the asymmetric demands of a modern "system". Modern OS's and computing usage can benefit hugely from architectures that can provide important (for a given value of important) processes with dedicated processing hardware since many functions are effectively functionally independant of each other. A multicore system could productively dedicate cores to some individual tasks - one for the User Interface alone, one for malware scanning, one for keeping track of crypto keys\ authentication\ authorization states, one for housekeeping and optimizing storage performance on the fly etc etc. So there are benefits to be gained from additional cores there that are different to those that Amdahl's law governs but I still can't see them raising the bar above 32 cores in total especially since most of the really useful things also require multiplication of other resources (memory, network bandwidth etc).
Now note that we have quad core x86 CPU's available today in the consumer market. At a guess that will double to 8 cores in 2007, and double again to 16 in 2009 so we'll probably be banging up against 32 cores for consumer hardware sometime in 2010 assuming that the performance drop off or the idle electrical power consumption at 16 cores doesn't put the brakes on sooner. To keep pace with Moore's law we would definitely need to hit 32 cores at a minimum by 2010.
The general purpose CPU market has had to freeze clock speeds in the 3-4Ghz range since 2002 because everyone has failed to build any that go faster efficiently. No one has any proven solution to that barrier today. So we are now looking at a situation where the current dominant architecture has no demonstrated way to increase desktop CPU performance significantly after 2010. There's nothing new there and the CPU business has never been clear about how it was going to be able to build something 5x more powerful four years in the future but I have a strong suspicion that these two issues today are much harder than the problems faced in the past.
There are already some extremely highly parallelizable tasks that end users want to use their systems for (3D graphics, ripping\transcoding of Video and Audio, Image Processing) and the ideal solution for these is to use dedicated (and highly parallel) hardware for some very limited tasks with a general purpose CPU managing the show. Sounds a lot like the
Cell CPU doesn't it?
I think that what will emerge is that we are going to see a major shake up in architectures over the next two to three years as the symmetric multi-core performance wall becomes undeniable. By the end of 2008 an asymmetric multi core client system architecture will emerge that will clearly define the shape of client desktop computing for the next decade, and that won't be simply a massive replication of x86 cores. The Cell could well turn out to have been well ahead of its time and what I'd love to see is an x86\GPU "hybrid" - say with a 16 core general purpose primary unit , a high speed ultra high bandwidth memory\IO controller and many simple cores (10's maybe hundreds) for highly compact integer and floating point matrix\vector cmputational tasks. We'll see.

